
Designing a Clean Data Lake for Retail Supply Chains
Retailers managing multiple brands face messy data:
Different naming conventions (e.g., “SKU” vs. “ProductCode”)
Inconsistent formats (JSON, CSV, Parquet)
Redundant or duplicate product records
Unreliable stock or transaction timestamps
At ManoloAI, we help retailers unify this fragmented data into a clean, query-ready data lake that supports ML models, dashboards, and agent workflows.
Our Solution: Lakehouse Pattern
What is a Data Lake?
A data lake is a data storage strategy whereby a centralized repository holds all of your organization's structured and unstructured data. It employs a flat architecture which allows you to store raw data at any scale without the need to structure it first. Instead of pre-defining the schema and data requirements, you use tools to assign unique identifiers and tags to data elements so that only a subset of relevant data is queried to analyze a given business question. This analysis can include real-time analytics, big data analytics, machine learning, dashboards and data visualizations to help you uncover insights that lead to better decisions.
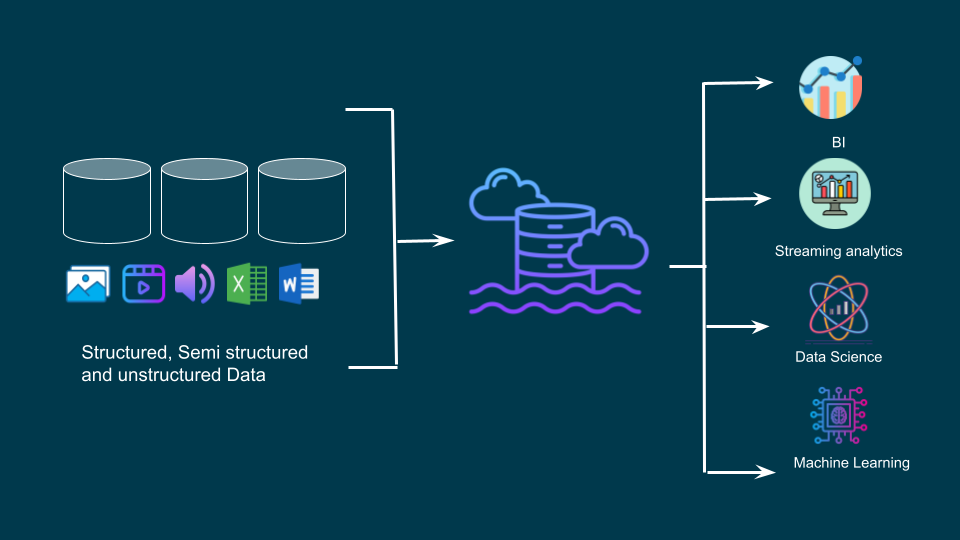
We follow a multi-layered data lake design:
Raw Layer → Cleaned Layer → Business-Ready LayerSample Python Pipeline (with Pandas & PyArrow)
#Simulated raw data sets from two brands brand_a = pd.DataFrame({ 'ProductCode': ['A001', 'A002'], 'Name': ['T-shirt', 'Jeans'], 'InventoryQty': [100, 50], 'LastUpdated': ['2025-07-01 10:00:00', '2025-07-01 11:00:00'] }) brand_b = pd.DataFrame({ 'SKU': ['B-1001', 'B-1002'], 'ProductName': ['Shirt', 'Denim Pants'], 'Stock': [200, 75], 'UpdatedAt': ['2025/07/01 09:30', '2025/07/01 10:45'] })
#Normalize Schemas def normalize_brand_b(df): df = df.rename(columns={ 'SKU': 'ProductCode', 'ProductName': 'Name', 'Stock': 'InventoryQty', 'UpdatedAt': 'LastUpdated' }) df['LastUpdated'] = pd.to_datetime(df['LastUpdated'], format="%Y/%m/%d %H:%M") return df
brand_b_clean = normalize_brand_b(brand_b) brand_a['LastUpdated'] = pd.to_datetime(brand_a['LastUpdated'])
#Merge and Deduplicate combined = pd.concat([brand_a, brand_b_clean]) combined.drop_duplicates(subset=['ProductCode'], keep='last', inplace=True)
#Save to Parquet os.makedirs("clean_layer", exist_ok=True) table = pa.Table.from_pandas(combined) pq.write_table(table, "clean_layer/products.parquet")
print("Data written to clean_layer/products.parquet")
Directory Layout (Lake Example)
What This Enables
With a clean data lake, you can now:
Query unified inventory in near real-time
Build forecasting or pricing models
Feed reliable inputs to AI agents
Generate clean dashboards across brands
Tip for Retailers:
Avoid dumping raw files into your lake, implement schema versioning, audit logs, and a data catalog for long-term value.